

I was researching for an article about image and object recognition, when I stumbled upon an inconsistency. In the Wikipedia article about optical character recognition (OCR) I read:
“In 1914, Emanuel Goldberg developed a machine that read characters and converted them into standard telegraph code.”
A few a few lines further it was stated that the same Emanuel Goldberg developed a machine (called “Statistical Machine”) for searching microfilm archives using an optical code recognition system. Furthermore it was stated that the Statistical Machine got patented in 1931.
Now I wanted to know more about these machines and immediately found lots of information about the Statistical Machine on the web. For instance about it’s intended purpose that was to retrieve accounting and sales statistics, therefore the name (source).
But for the first machine I found absolutely nothing, only dozens of articles with copies of the sentence from Wikipedia. This was strange, why were there no sketches and no technical details available, when it was such a noteworthy invention?
I studied the footnotes. In the Wikipedia article the indicated source for the information about the machine of 1914 was:
Dhavale, Sunita Vikrant (2017). Advanced Image-Based Spam Detection and Filtering Techniques. Hershey, PA: IGI Global. p. 91.
I quickly found the passage in the book by Dr. Dhavale and read about the same:
“In 1914, Emanuel Goldberg developed a machine to convert printed characters into standard telegraph code.”
She presented another source for this: Schantz, Herbert F. (1982). The history of OCR, optical character recognition
„Okay, we are getting closer“, I thought. Thanks to ebook lending I was able to look that up promptly. The answer may not surprise you. Herbert F. Schantz states crystal clear that it was Goldberg who invented a machine that reads and converts typed messages to standard telegraph code (Morse code):

One can see that the year for the invention now has changed from 1914 to 1912. – A few lines above Schantz mentions a time window (between 1912 and 1914) to include the invention of the optophone by Edmund Fournier d’Albe:

I assume this is how the year 1914 got into the book of Dhavale. Please also note that the forename is misspelled. His correct name is Emanuel Goldberg.
But what really astonished me, was the notion that the work was done in Chicago. Emanuel Goldberg was Professor at Leipzig (Germany) during that time, why should he work in Chicago?
At this point I already sensed that Schantz’s research for this chapter was deeply flawed. – I decided to consult the only comprehensive biography of Emanuel Goldberg that is available. It was written by Berkeley professor Michael Buckland and published in 2006. The title of the book: Emanuel Goldberg and his Knowledge Machine.
Of course “knowledge machine” refers to Goldberg’s Statistical Machine. (For those who are interested in the operating principles of that machine: the technical details can be found on this page). Anyway. I leafed through the book. It was was arranged more or less chronologically and I found nothing about Goldberg spending time in Chicago or working on a machine that converts characters to Morse code.
I was already in the 1930s and half through the book as Buckland suddenly quotes from this passage of the book of Herbert F. Schantz:

The passage starts with the notion that Goldberg was „already known for the invention of OCR-type telegraphic devices.“ But other than Dr. Dhavale Prof. Buckland realized that Schantz had messed it up. Buckland knew that two inventive Goldbergs existed, both working on optical recognition systems. The famous one is of course Emanuel Goldberg. The almost forgotten one is Hyman Eli Goldberg (also known as Hyman Golber, due to a later change of name).
Here is, what Buckland states with regard to Schantz’s confusion:
“For once in his life, Goldberg received more than his fair share of credit, because two inventive Goldbergs working on pattern recognition devices have not been adequately distinguished. The other Goldberg was Hymen [sic] Eli Goldberg of Chicago, who was associated with the Goldberg Calculating Machine Company and changed his name to Hymen Eli Golber. Golber obtained numerous U.S. and German patents, most of them in the years 1907 to 1914 and 1930, for innovations in calculating and printing machinery. One of his techniques was to print characters in electrically conducting ink on a nonconducting surface. A sensor would then test whether surface points were conductive or not, thereby detecting the location and shape of printed characters.”
Buckland 2006, p. 162
Note that Buckland got the forename wrong. Hyman is correct.
Long story short: It was Hyman Eli Goldberg who patented a machine that converts characters into telegraph code.
And this is the corresponding patent: it was filed as „Controller“ in 1911 and granted in 1915: patents.google.com/patent/US1165663A (a precursor version is patented under US1117184.)

By the way: the machine can NOT process standard print or typewrite letters. The conversion works due to a specifically shaped set of letters and digits that is presented on page 3 of the patent file:
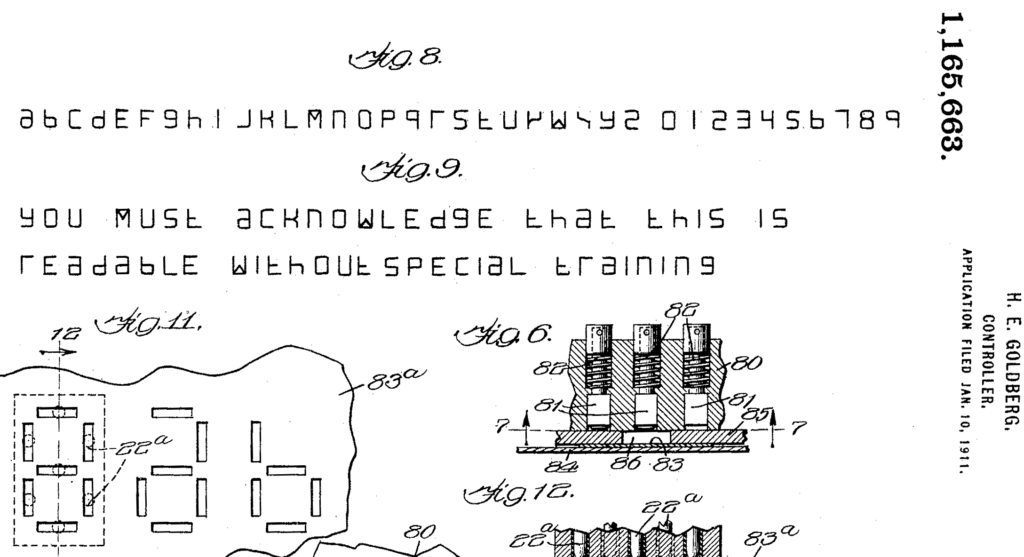
For further reading: there is at least one publication (from Dennis Yi Tenen, Columbia University) that acknowledges, explains and credits the invention of Hyman Eli Goldberg properly: amodern.net/article/laminate-text
Conclusion: It is a bit frustrating that Michael Buckland’s finding did not make it into the Wikipedia (as of 11/11/2022). The false claim is now spread over the Internet and will never vanish completely.
So what can be learned from this? – Well, obviously this: do not trust every information that is in the Wikipedia, always look for the original source, if something looks inconsistent, dig deep.


